Unity粒子系统
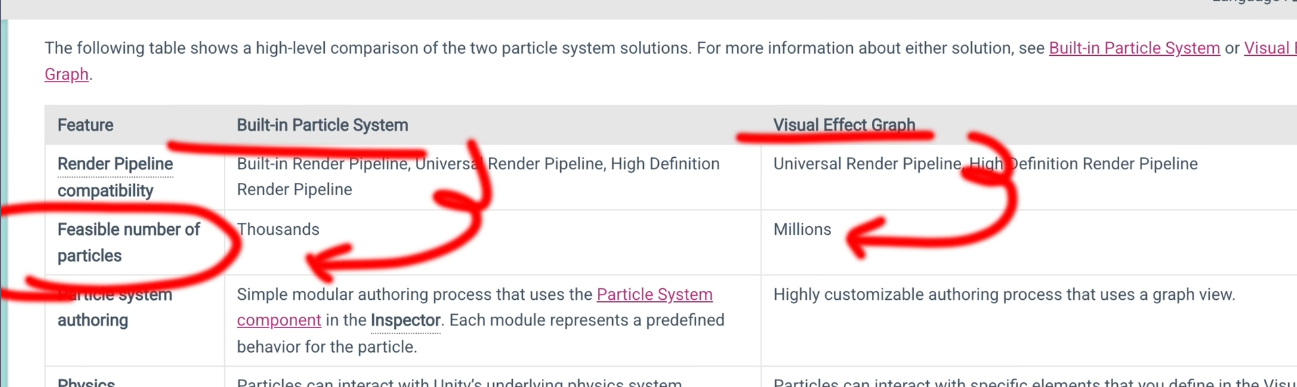
- Unity有两套粒子系统
- CPU粒子的ParticleSystem,能支撑粒子的数量级是几千个
- GPU粒子的Visual Effect Graph(VFX Graph),能支撑粒子的数量级是几百万个
粒子是什么
- 粒子系统是由大量运动颗粒构成的
从编程角度来看
- 分为三部分
- 数据
- 逻辑
- 表现
数据:
- 结构体,必须有一个Vector3的Position属性
- 其他属性,可以有Color、Scale
假设有一个例子系统,由10万个这样的粒子构成
那一个Particle结构体的数组,长度为10万,就构成了粒子系统的全部数据
1 | struct Particle |
逻辑:
- 根据某种规律,每一帧,计算position属性,让这些数据“运动”起来
1 | class Particle |
表现:
- 如何结合图像API把刚才10万个粒子的数据展示出来,比如把每个例子渲染成点图元、面片等
CPU粒子和GPU粒子的实现有很大区别
CPU粒子

工作流程:
- 第一步:在内存里初始化10万个粒子对象
- 第二步:每一帧里更新十万个粒子的位置
- 第三步:每一帧要把变换的数据提交给GPU,让GPU做渲染
开销影响:
- 由于第二步的计算每一帧都要计算,而CPU无法进行并行计算,所以粒子数量多时,计算开销非常大
- 第三步数据计算之后,需要从CPU把计算的结果提交给GPU做显示,这样的显示每一帧都要做,都涉及到跨CPU和GPU的通信
GPU粒子

工作流程:
- 第一步:虽然也需要声明10w万个粒子的数据,但是会在初始化的时候,一次性的把这些数据从内存拷贝到GPU显存侧的ComputeBuffer里
- 第二步:计算每一个粒子下一帧所应该在的位置,计算后的结果依然存储在GPU的显存的ComputeBuffer里面
- 第三步:渲染的时候直接从显存的ComputeBuffer里面拿数据,直接渲染
开销影响:
- 第二步由于发生在GPU侧,可以充分利用GPU里面的ComputeShader并行计算能力
- 第三步减少了CPU到GPU的数据拷贝
借助ComputeShader和ComputeBuffer实现GPU粒子的细节
- 还是从数据、逻辑、表现三块来看
数据

- 需要一个结构体particle,里面至少要包含一个Position属性
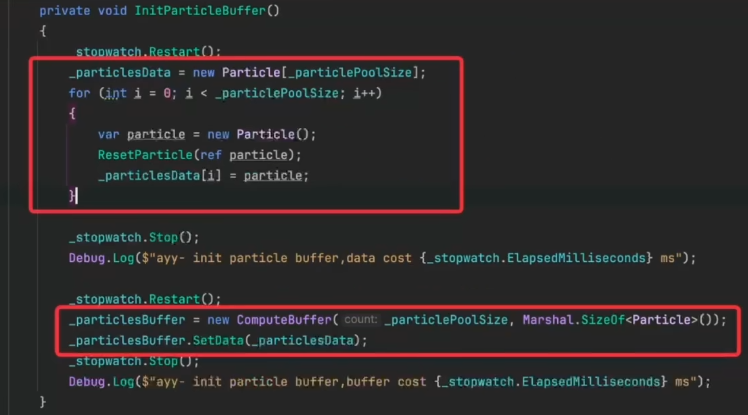
- 初始化数据,初始化ComputeBuffer,填充数据
- 把结构体数据填充到内存里,并拷贝到ComputeBuffer里
- new ComputeBuffer()
- 第一个参数是要缓存多少个这样的粒子,ComputeBuffer的长度要和粒子的长度一样
- 第二个参数是Particle结构体的大小
- new完后只是说显存里有这个Buffer了,还要把数据真正拷贝过去
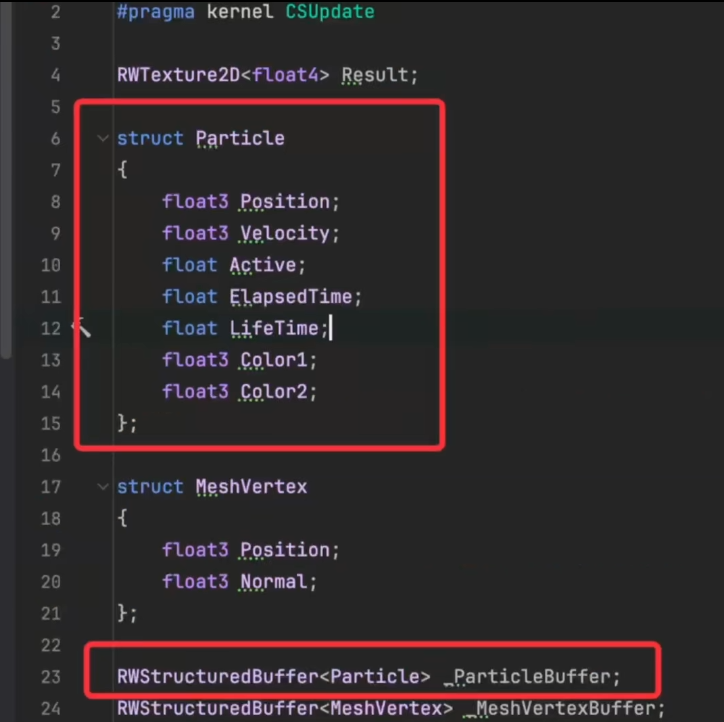
- 为了能在ComputeShader计算的时候能使用上刚才ComputeBuffer里的数据,需要新建一个ComputeShader,也写上一个同样的struct
- 写一个RWStructure的Buffer,把Particle当做泛型传进来,相当于准备好一个Particle List去容纳CPU传过来的数据
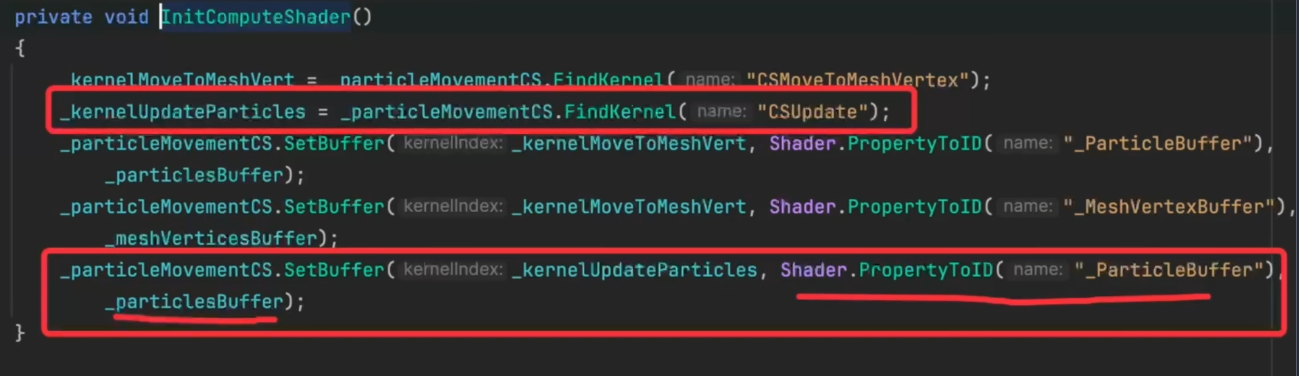
- 在C#里准备好了ComputeBuffer、在ComputeShader里准备好了StructureBuffer之后,需要把二者关联起来
逻辑
- 如何每帧更新粒子位置

- 在CPU大概会写成这个样子

- 变成GPU粒子后,Update函数有比较大的变化
- 不会在Update里面做for循环了,只需要给ComputeShader设置deltaTime,然后调用Dispatch,传一个ComputeShader的函数名,这样ComputeShader就会去工作,自动去算每个粒子的位置了