Unity中的渲染优化技术
16.1 移动平台的特点
- 和PC平台相比,移动平台上的GPU架构有很大的不同
- 由于处理资源等条件的限制,移动设备上的GPU 架构专注于尽可能使用更小的带宽和功能,也由此带来了许多和PC平台完全不同的现象
- 比如,我们需要为了尽可能移除那些隐藏的表面从而减少overdraw,PowerVR芯片使用了基于瓦片的延迟渲染架构,它会把所有渲染图元装入一个个瓦片中,再由硬件找到可用的片元,而只有这些可见片元才会执行片元着色器
- 另一些基于瓦片的GPU架构则会使用Early-Z或相似的技术实现一些低精度的深度检测,来剔除不需要的渲染片元
- 还有一些GPU,如英伟达的芯片,则使用了传统的架构设计,因此在这些设备上,overdraw就会造成更多的性能瓶颈
- 因为芯片的架构不同,游戏往往需要针对不同的芯片发布不同版本,以便对每个芯片进行更有针对性的优化
16.2 影响性能的因素
- 对一个游戏来说,它最主要需要的是两种资源,分别是CPU和GPU,它们会互相合作,来让游戏可以在预期的帧率和分辨率下工作
- 其中CPU主要负责保证游戏的帧率,GPU主要负责分辨率相关的处理,据此可以把游戏性能瓶颈分为以下几个方面:
- CPU
- 过多的draw call
- 复杂的脚本或者物理模拟
- GPU
- 顶点处理
- 过多的顶点
- 过多的逐顶点计算
- 片元处理
- 过多的片元,既可能是由于分辨率造成的,也可能是由于overdraw造成的
- 顶点处理
- 带宽
- 使用了尺寸很大且未压缩的纹理
- 分辨率过高的帧缓存
- CPU
- 优化技术有:
- CPU优化
- 使用批处理技术减少draw call数目
- GPU优化
- 减少需要处理的顶点数目
- 优化几何体
- 使用模型的LOD(Level of Detail)技术
- 使用遮挡剔除(Occlusion Culling)技术
- 减少需要处理的片元数目
- 控制绘制顺序
- 警惕透明物体
- 减少实时光照
- 减少计算复杂度
- 使用Shader的LOD技术
- 代码方面的优化
- 减少需要处理的顶点数目
- 节省内存带宽
- 减少纹理大小
- 利用分辨率缩放
- CPU优化
16.3 Unity中的渲染分析工具
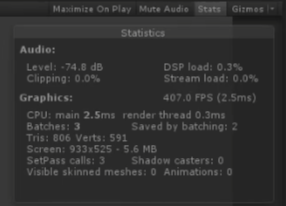
- 渲染统计窗口(Rendering Status Window)
- 主要关注Graphics图像部分
- Batch:一帧中需要进行批处理的数目
- Saved by batching:合并的批处理数目,这个数字表面了批处理为我们节省了多少draw call
- Tris及Verts:需要绘制的三角面片和顶点数目
- Screen:屏幕的大小及它所占用的内存大小
- SetPass:渲染所使用的Pass数目,每个Pass都需要UnityRuntime来绑定一个新的Shader,这就可能造成CPU的瓶颈
- Visible skinned meshes:渲染的蒙皮网格的数目
- Animations:播放的动画数目
- 性能分析器
- 值得注意的是,性能分析器给出的draw call数目和批处理数目、Pass数目并不相等,而且看起来好像要大于我们估算的数目。这是因为Unity在背后需要进行很多的工作,比如初始化各个缓存、为阴影更新深度纹理和阴影映射纹理等等,因此需要花费比预期更多的draw call
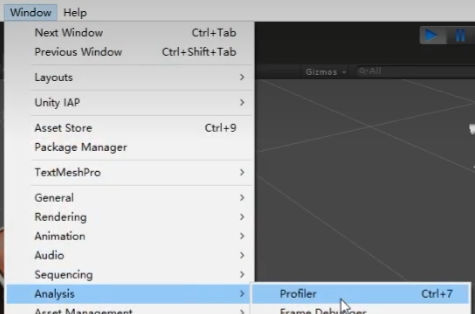
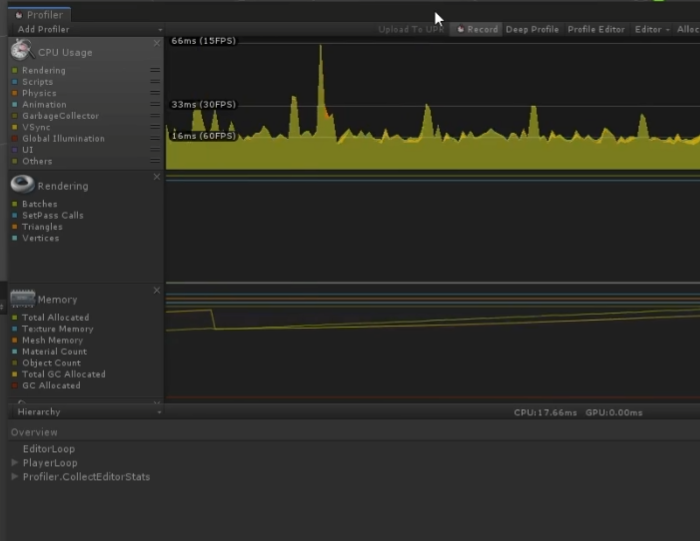
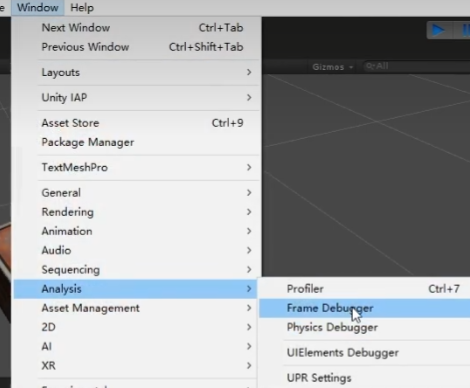
- 因此,有一个更好的工具做查看,帧调试工具Frame Debugger
- 为了得到真机上的结果,也有一些其他的分析工具
- Adreno分析工具
- NVPerfHUD工具
- Unity内置的分析器
- PowerVRAM的PVRUniSCo shader分析器
- Xcode中的OpenGL ES Driver Instruments
16.4 减少draw call数目
16.4.0
- 批处理的实现原理就是为了减少每一帧需要的draw call数目。为了把一个对象渲染到屏幕上,CPU需要检查哪些光源影响了该物体,绑定shader并设置它的参数,再把渲染命令发送给GPU
- 当场景中包含了大量对象时,这些操作就会非常耗时,这时draw call数就会成为性能瓶颈
- 因此批处理的原理很简单,就是在每次调用draw call时尽可能的去处理多个物体
- 什么样的物体可以一起处理呢?答案就是使用同一个材质的物体。这是因为这些物体之间的不同仅仅在于顶点数据的差异,我们就可以把这些顶点数据合并在一起,再发送给GPU,就可以完成一次批处理
- Unity中支持动态批处理和静态批处理
16.4.1 动态批处理
- 优点是一切都由Unity自动完成,不需要自己操作,而且物体是可以移动的
- 缺点是限制过多,一不小心就会破坏机制,导致Unity无法动态批处理一些使用相同材质的物体
- 随着Unity版本的迭代,这些限制条件也在改变
- 主要的限制在于,能够进行动态批处理的网格的顶点属性规模要小于900;如果在Shader中需要使用顶点位置、法线、纹理坐标这三个顶点属性时,它们的顶点属性不能超过300
- 在早期版本,所有的对象都需要使用同一个缩放尺度,现在已经不需要了
- 使用光照纹理的物体需要小心处理,因为需要额外的渲染参数,以及多Pass的Shader会中断批处理
16.4.2 静态批处理
- 优点是自由度很高,限制很少
- 可能会占用更多的内存,且经过静态批处理的物体不可以再移动了
- 相比于动态批处理来说,静态批处理适用于任何大小的几何模型。它的实现原理是,只在运行开始阶段,把需要进行静态批处理的模型合并到一个新的网格结构中,这意味着这些模型不可以在运行时刻被移动
- 但由于它只需要进行一次合并操作,因此,比动态批处理更加高效。静态批处理的另一个缺点在于,它往往需要占用更多的内存来存储合并后的几何结构
- 在内部实现中,Unity首先会把静态空间下的物体变换到世界空间下,然后为它们构建一个更大的顶点和索引缓存,对于使用了同一个材质的物体,Unity只需要使用一个draw call就可以绘制全部的物体;而对于使用不同材质的物体,静态批处理同样可以提升渲染性能,尽管这些物体仍然需要调用多个draw call,但静态批处理可以减少这些draw call之间的状态切换,这些切换往往是费时的操作
- VBO是顶点缓冲对象,使用静态批处理会占用更多内存,会导致VBO数目上升。同时,如果增加一个光源的话也并没有什么关系,因为Base Pass的部分仍然会被静态批处理
16.4.3 共享材质
- 可以发现,无论是静态批处理还是动态批处理,都要求模型之间需要共享一个材质,但不同模型之间总会有不同的渲染属性,就比如使用了不同的纹理颜色等等,这时需要一些策略来尽可能的合并材质
- 如果两个材质只有使用的纹理不同,就可以把这个纹理合并到一张更大的纹理中,也就是称为图集的东西。一旦使用了同一张纹理,就可以使用同一个材质,再使用不同的采样坐标,就可以对纹理进行采样
- 但有时除了纹理不同,不同的物体在材质上还有一些微小的参数变化
- 不管是动态批处理还是静态批处理,它们的前提都是要使用同一个材质
- 是同一个材质,而不是使用了同一种Shader的材质,也就是说它们指向的材质必须是同一个实体
- 这意味着,只要我们调整了参数,就会影响到所有使用这个材质的对象。那么想要微小的调整怎么办呢?
- 一种常用的方法就是使用网格的顶点数据(最常见的就是顶点颜色数据)来存储这些参数
- 经过批处理后的物体会被处理成更大的VBO发送给GPU,VBO的数据可以作为输入传递给顶点着色器,因此就可以巧妙地对VBO中的数据进行控制,从而达到不同效果的目的
- 比如,森林场景中所有的树都使用了同一种材质,不同的树颜色可能是不同的,但我们希望它们可以通过批处理减少draw call,这时我们可以利用网格的顶点的颜色数据进行调整
- 值得注意的是,如果在脚本中访问共享材质的话,根据访问方式的不同,就有可能会将修改应用到所有的使用该材质的物体上,也有可能会创建一个该材质的复制品,从而破坏批处理在该物体上的应用
16.4.4 批处理的注意事项
- 尽可能选择静态批处理,但得时刻小心对内存的消耗,并且记住经过静态批处理的物体不可以再被移动
- 如果无法进行静态批处理,而要使用动态批处理的话,那么请小心上面提到的各种条件限制。尽可能让这些物体包含少量的顶点质性和顶点数目
- 对于游戏中的小道具,例如可以捡拾的金币等,可以使用动态批处理
- 对于包含动画的这类物体,我们无法全部使用静态批处理,但其中如果有不动的部分,可以把这部分标识成”Static”
- 由于批处理需要把多个模型变换到世界空间下才合并它们,因此如果Shader中存在一些基于模型空间下的坐标的运算往往会得到错误的结果,可以使用Shader中的Disable Batching标签来强制使用该系列的材质,不会被批处理
- 使用半透明材质的物体,通常需要严格的,从后往前的顺序绘制,从而保证透明混合的正确性。对于这些物体,Unity会首先保证绘制的正确性,再尝试对它们进行批处理。这也意味着,当渲染顺序无法满足时,批处理就无法在这些物体上成功的运用
16.5 减少需要处理的顶点数目
16.5.1 优化几何体
- 尽可能减少模型中三角面片的数目,一些对于模型没有影响、或是肉眼非常难察觉到区别的顶点都要尽可能去掉
- 移除不必要的硬边以及纹理衔接,避免边界平滑和纹理分离
16.5.2 模型的LOD技术
- 当一个物体离摄像机很远时,模型上的很多细节是无法被察觉到的。因此,LOD允许当对象逐渐远离摄像机时,减少模型上的面片数量,从而提高性能
- Unity中的LOD Group组件
16.5.3 遮挡剔除技术
- 遮挡剔除可以用来消除那些在其他物件后面看不到的物件,这意味着资源不会浪费在计算那些看不到的顶点上,进而提升性能
- 要区分视椎体剔除和遮挡剔除
- 视椎体剔除只会剔除那些不在摄像机视野范围内的物体,但不会判断视野中是否有物体被其他物体挡住而剔除
- 而遮挡剔除会使用一个虚拟的摄像机来遍历场景,从而构建一个潜在可见的对象集合的层级结构,在运行时刻,每个摄像机将会使用这个数据来识别哪些物体是可见的,哪些是被其他物体挡住不可见的
- 使用遮挡剔除技术不仅可以减少处理的顶点数目,还可以减少overdraw
16.6 减少需要处理的片元数目
16.6.0
- 另一个造成GPU瓶颈的是需要处理过多的片元
- 这部分优化的重点在于减少overdraw
- 简单地说,overdraw指的是同一像素被绘制了多次
16.6.1 控制绘制顺序
- 为了最大限度地避免overdraw,一个重要的优化策略就是控制绘制顺序
- 由于深度测试的存在,如果我们可以保证物体都是从前往后绘制的,那么就可以很大程度上减少overdraw
- 这是因为,在后面绘制的物体由于无法通过深度测试,因此,就不会再进行后面的渲染处理
- 对于渲染队列小于2500的物体,它们都是从前往后绘制的,而其他的则是从后往前绘制的
16.6.2 时刻警惕透明物体
- 对于半透明对象来说,由于它们没有开启深度写入,因此,如果要得到正确的渲染效果,就必须从后往前渲染
- 这意味着,半透明物体几乎一定会造成overdraw
- 如果我们不注意这一点,在一些机器上可能会造成严重的性能下降
16.6.3 减少实时光照和阴影
- 实时光照对于移动平台是一种非常昂贵的操作。如果场景中包含了过多的点光源,并且使用了多个Pass的Shader。那么很有可能会造成性能下降
- 可以用烘焙技术,把光照提前烘焙到一张光照纹理上,在运行时刻只需要根据纹理去采样得到光照结果就可以了
- 另一种方法是使用GodRay,场景中很多小型的光源效果都是靠这种方法来模拟的,它们一般并不是真的光源,很多时候是通过透明纹理的模拟来得到的
- 在实际的游戏中,很多看起来非常复杂的高级的光照计算都是优化后的结果,开发者们通过把复杂的光照计算存储到一张查找纹理中,也就是LookUpTexture(LUT),在运行时刻只需要使用光源方向、视角方向和法线方向等参数对LUT进行采样,就可以得到光照效果。可以给影响中的主角使用更大分辨率的LUT,而一些NPC则使用较小的LUT
- 实时阴影也是一个非常消耗性能的结果,不仅使CPU需要提高更多的draw call,GPU也需要进行更多的处理,因此我们应该尽量减少实时阴影。例如,通过烘焙把静态物体的阴影信息存储到光照纹理中,而只对场景中的动态物体使用适当的实时阴影
16.7 节省带宽
16.7.1 减少纹理大小
- 之前提到过,使用纹理图集可以帮助减少draw call的数目,而这些纹理的大小同样是一个需要考虑的问题
- 需要注意的是,所有纹理的长宽比最好是正方形,而且长宽值最好是2的整数幂。这是因为有很多优化策略只有在这种时候才可以发挥最大效用
- 使用MipMap
- 不同的纹理压缩格式
16.7.2 利用分辨率缩放
- 过高的屏幕分辨率也是造成性能下降的原因之一,尤其是对于很多低端手机。除了分辨率高其他硬件条件并不尽如人意,而这恰恰是游戏性能的两个瓶颈:过大的屏幕分辨率和糟糕的GPU
- 因此,我们可能需要对于特定机器进行分辨率的放缩。当然,这样可能会造成游戏效果的下降,但性能和画面之间永远是个需要权衡的话题
16.8 减少计算复杂度
16.8.1 Shader的LOD技术
- Shader的LOD技术可以控制使用的Shader等级。它的原理是,只有Shader的 LOD值小于某个设定的值,这个 Shader才会被使用,而使用了那些超过设定值的Shader的物体将不会被渲染
- 在Shader中使用,只需加上LOD标签,比如LOD 200,这样的话只有Shader的LOD值小于设定的值,这个Shader才会被使用,而超过设定值的物体不会被渲染
16.8.2 代码方面的优化
- 在实现游戏效果时,我们可以选择在哪里进行某些特定的运算。通常来讲,游戏需要计算的对象、顶点和像素的数目排序是对象数<顶点数<像素数
- 因此,我们应该尽可能地把计算放在每个对象或逐顶点上
- 首先第一点是,尽可能使用低精度的浮点值进行运算
- 对于绝大多数GPU来说,在使用插值寄存器把数据从顶点着色器传递始下一个阶段时,我们应该使用尽可能少的插值变量
- 尽可能不要使用全屏的屏幕后处理效果。如果美术风格实在是需要使用类似 Bloom、热扰动这样的屏幕特效,应该尽量使用fixed/ lowp进行低精度运算(纹理坐标除外,可以使用half/mediump)。那些高精度的运算可以使用查找表(LUT)或者转移到顶点着色器中进行处理
16.8.3 根据硬件条件进行缩放
- 一个非常简单且实用的方式是使用所谓的放缩(scaling)思想
- 我们首先保证游戏最基本的配置可以在所有的平台上运行良好,而对于一些具有更高表现能力的设备,我们可以开启一些更”养眼”的效果,比如使用更高的分辨率,开启屏幕后处理特效,开启粒子效果等