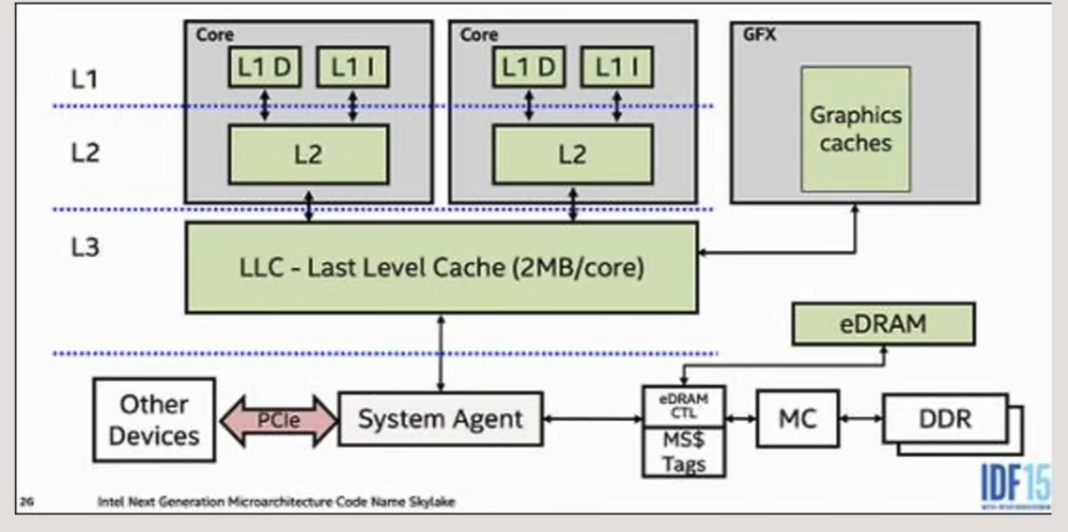
如何理解L1、L2、L3级缓存的这种树形结构设计
- CPU指令执行也是在排队,很多算法也都是在处理数据队列
- 现实中各种队列的内外因素不同,我们可以通过一些设计、规则、以及调度的调整,去改善队列的效率
- 计算机上也一样,dots面向数据的设计部分,就是在设计队列的结构,ECS就是在组织队列中的规则,Job System就是在做队列的调度
队列类型
- 单队列
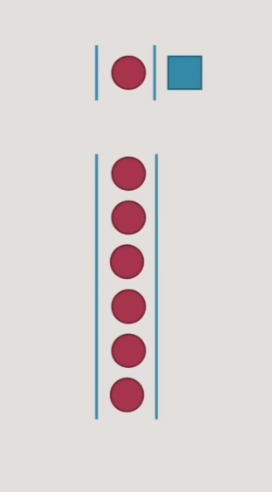
- 这样的队列比较简单,参与队伍管理的工作人员也可以很少
- 但队列中的任何一个人或业务人员出现了处理时间较长的问题,造成的阻塞会是整个系统级别的
- 这时,很容易就能想到用多条队列并行处理不就解决了吗
- 多队列
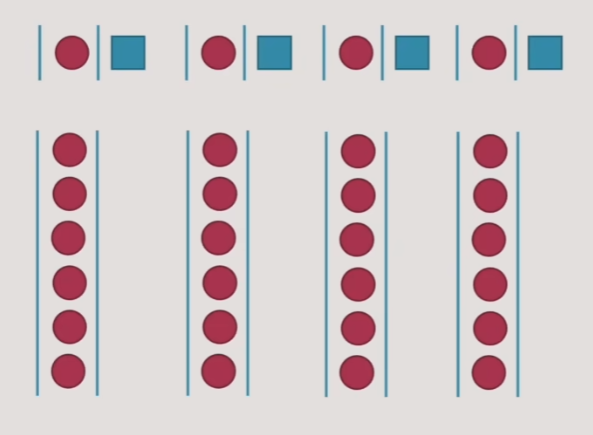
- 当初的计算机与CPU设计人员也是这么想的,并行计算、多核设计也是这么干的
- 但多行队列的占地会比较大,需要的服务人员与并行队列数量成正比
- 换到CPU上,就需要有更好的工艺,给多核留更大的空间
- 即使这样,单纯的多队列也并不一定能够高效,原因是木桶能装多少水要看最短的短板,我们不知道系统中每个人需要花费多久时间完成,当一个并行队列中,一个人花费时间太长时,也会造成整体的系统依旧很慢
- 这时处理并行,调度串行的队列就派上用场了
3.单队列+调度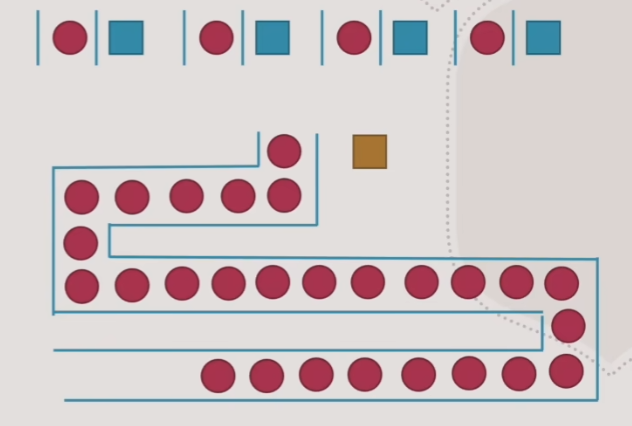
- 这种队列需要一个如图中黄色的调度人员来管理队列,当某人窗口被阻塞时,调度人员会将长队列等待的人调到其他处理窗口中
- 长的单行队列,就很像队列的Catch缓存
- 与多行并行队列相比,这种队列更适合队伍中每个人员处理时间长度不一致,以及新到队列中的人到来时间随机的情况,这种情况下单行调度队列比纯并行队列更有效
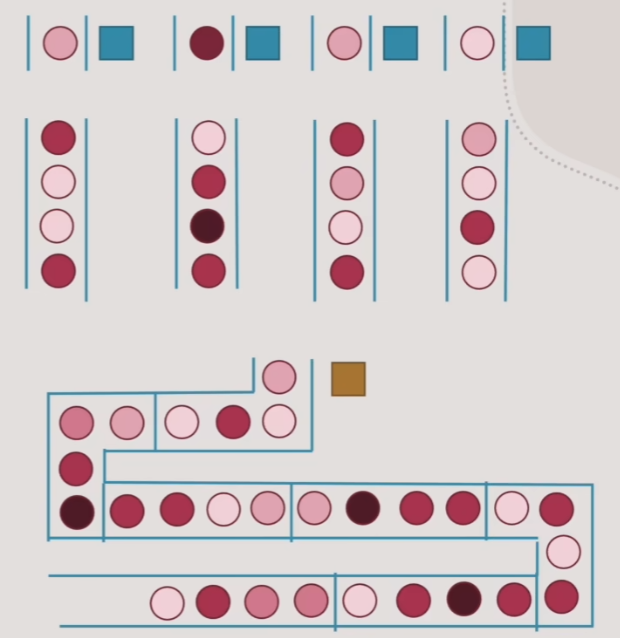
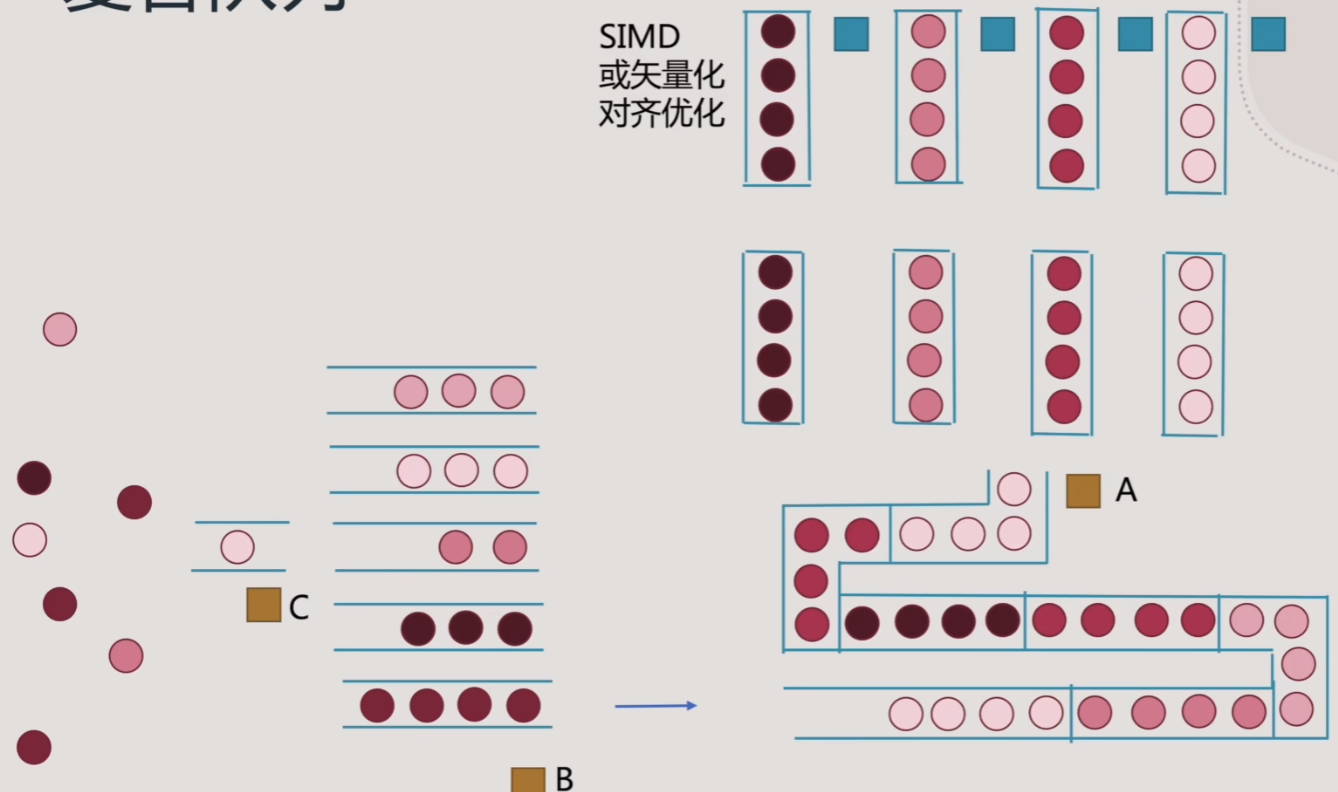
4.复合队列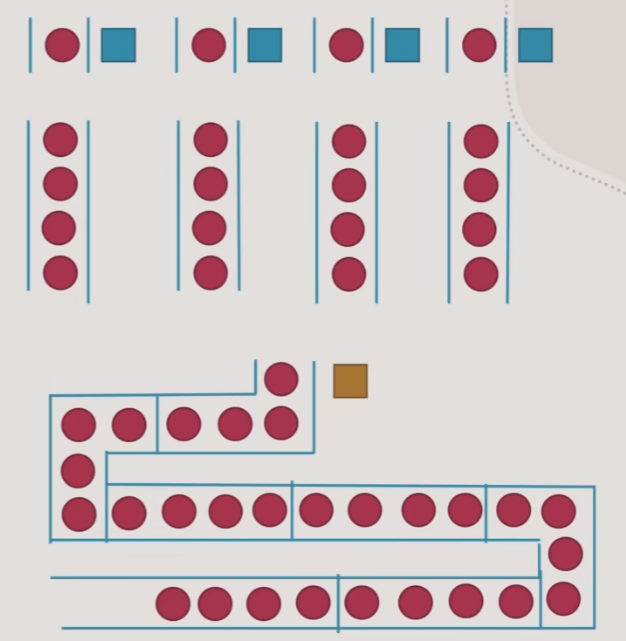
- 就是单行调度队列加上多行并行队列的组合,如现实中的做核酸队列
- 这种队列比较适合多阶段批次处理事务的队列,每个批次内每个人处理的时间近似的情况
- 这种复合队列中的并行队列,有点catch line的概念了
- 不过一旦出现每个人处理时间有巨大差异时,队列效率就会变得很差了,调度员的调度工作与复杂度也会上升
- 这时我们的队列可以做进一步演化
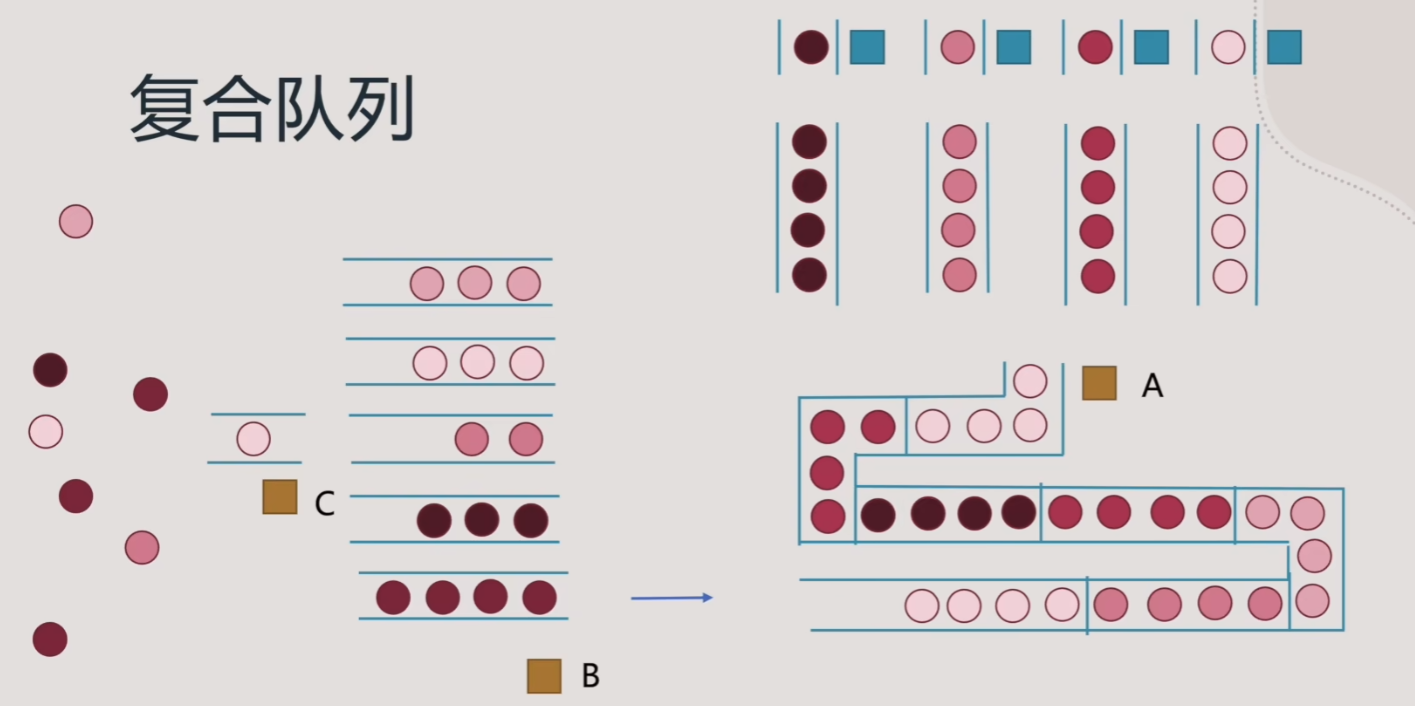
- 可以再增加一层并行队列,并增加两个调度人员,一个是应付进入整体队列系统的调度人员C,用来调度随机到来的人员进入类似属性的队列;另外一个调度员B则按照每个并行队列中,单个队列是否达到上限,将队列中的人统一调度到下一层的单行队列中进行等待
- 增加处理完队列后的后续工作,虽然队列按相同的属性组织完成了,但离开队列系统的情况是离散的,导致离开后队列变乱了,进而导致后续的系统效率又变差了
- 那么我们考虑在进入第一次并行队列时,按属性组分离队列的话,类比到CPU上,就是把数据组织成矢量,做对齐优化,处理时又可以兼容SIMD指令处理,这样一个指令处理多条类似数据,不仅加快了处理效率,还可以保持离开队列系统时数据的连续
- 最后,做一个更大胆的类比
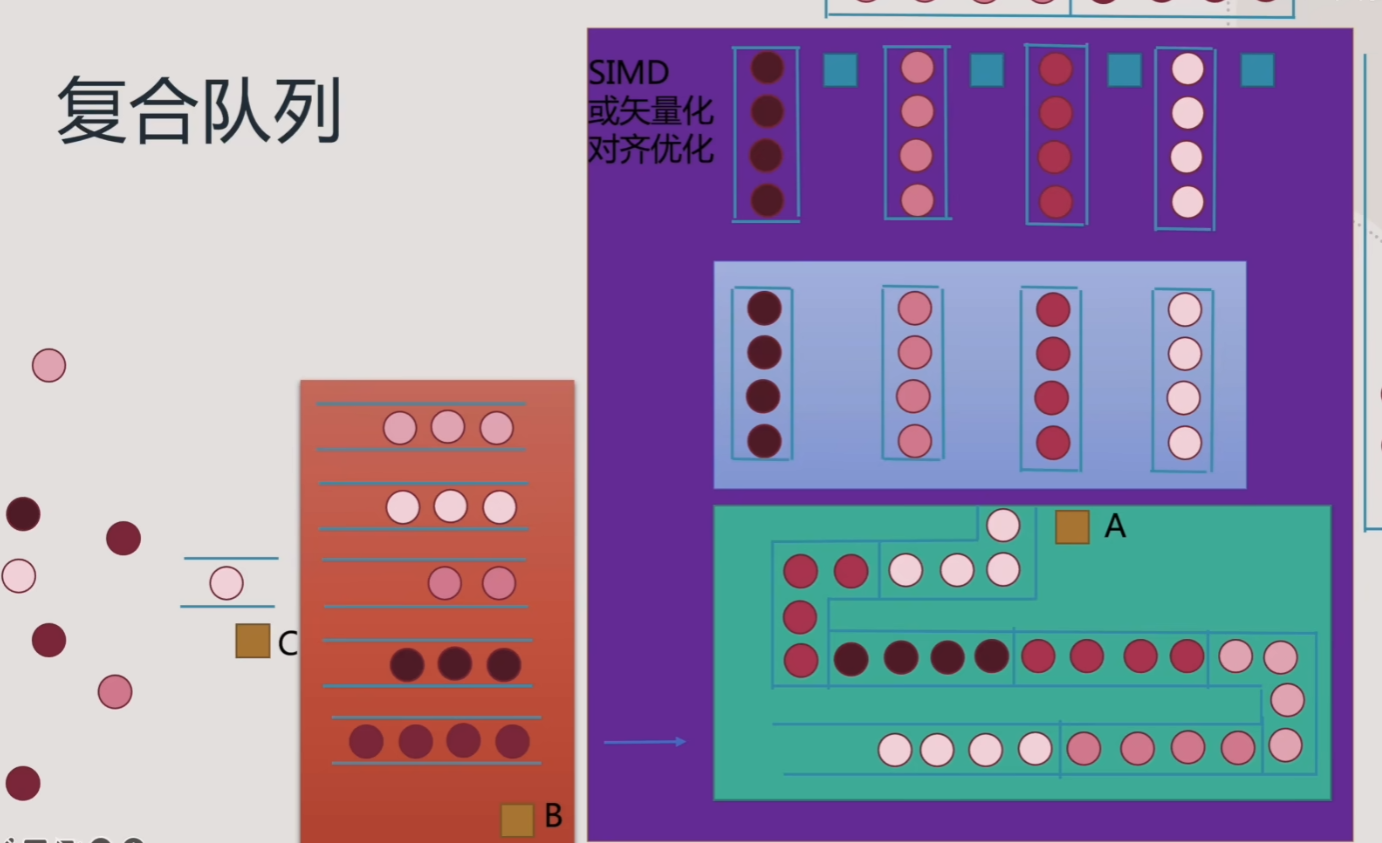
- 可以将蓝色部分类比成L1级缓存,青色部分类比成L2级缓存,紫色部分理解为一个CPU的逻辑盒,红色部分就是逻辑盒共享的L3级缓存了
- 而每个不同级别的缓存内的队列,可以类比成catch line,或者Archetype Chunk的概念
- 而整个队列系统组织数据Layout的过程,可以理解成ECS
- 黄色调度员类比成不同调度方式下的Job System
- 进入到蓝色处理员处理的人员队列,类比成Burst编译器优化过后的,支持SIMD的代码指令
- 总之,Catch为什么会设计成这样的层级结构,是由不同核、不同计算单元的不同情况下,不同数据与指令的调度需求决定的
- 类比不能代表真实情况,只是帮助理解
- 一般来说,不同的队列结构设计依赖单通道、多通道与单阶段、多阶段两个维度,在现实生活中都能找到类似的实例 :

- 队列模型建模考虑的因素 :
- 到达分布
- 到达规模
- 队列中人员耐心程度
- 有限/无限队长
- 队列结构
……