DOTS是面向数据的技术栈
DO的缩写正是DOTS是以面向数据为基础的一个技术解决方案
所以充分了解面向数据设计DOD是学习DOTS的基础
程序设计方法
- 这些程序设计方法都有很明显的时代特征,与程序语言的特性
- Instructional Programming
- 指令化编程
- 正是计算机脱离纸带打孔输入后,伴随着机器汇编语言发展起来的
- Functional Programming
- 函数化编程
- 伴随着Pascal语言出现的,以小函数模块化组合的编程范式
- 由于其限制小、易于调试等特点,主要用在数学和科学计算领域
- 如今如火如荼的机器学习、AI领域,函数化编程依然焕发着活力
- Procedural Programming
- 过程化编程
- 是一种源于命令式的编程范式,基于过程调用的概念,包含一些要执行的步骤,任何给定的过程都可以在程序执行过程中的任何时刻调用
- 过程化编程伴随着一些更高级的编程语言,如Fortran、ALGOL、COBOL、BASIC等而出现
- Object-Oriented Programming/Design
- 面向对象编程/设计(OOP/OOD)
- 随着程序化规模越来越大,传统的编程范式已不足以满足易于理解、易于设计的需要了,这时,面向对象设计和编程的方式开始出现了
- 它是以对象为概念的多范式模型,包含字段形式的数据与过程形式的代码,通常以类为基础,强调数据的封装、类的继承与对象的多态特征,程序开始有了更高级的设计的概念
- 随之是一系列相关设计模式,诸如C++、Java、Python等广泛使用的面向对象的多范式编程语言的出现
- Data-Oriented Design(DOD)
- 面向数据设计
- 是伴随着现代CPU多核并行计算、多级缓存、大缓存的设计而流行起来的
- 这里的DOD并不是面向数据编程,它并不是一种编程范式,而DOTS更可以理解为面向数据编程的一种范式
OOD -> DOD
- 我们需要有从OOD面向对象设计到DOD面向数据设计的思想转变
- 面向对象设计的核心在于抽象、封装和继承,这样的设计对人类来说可能更直观、易于理解,但对于现代CPU来说,它的处理效率并不高效
- 而面向数据设计则侧重于数据,开发人员需要考虑需要什么数据,以及如何在内存中更好的构造数据,以便CPU处理数据系统时能够更有效地访问数据
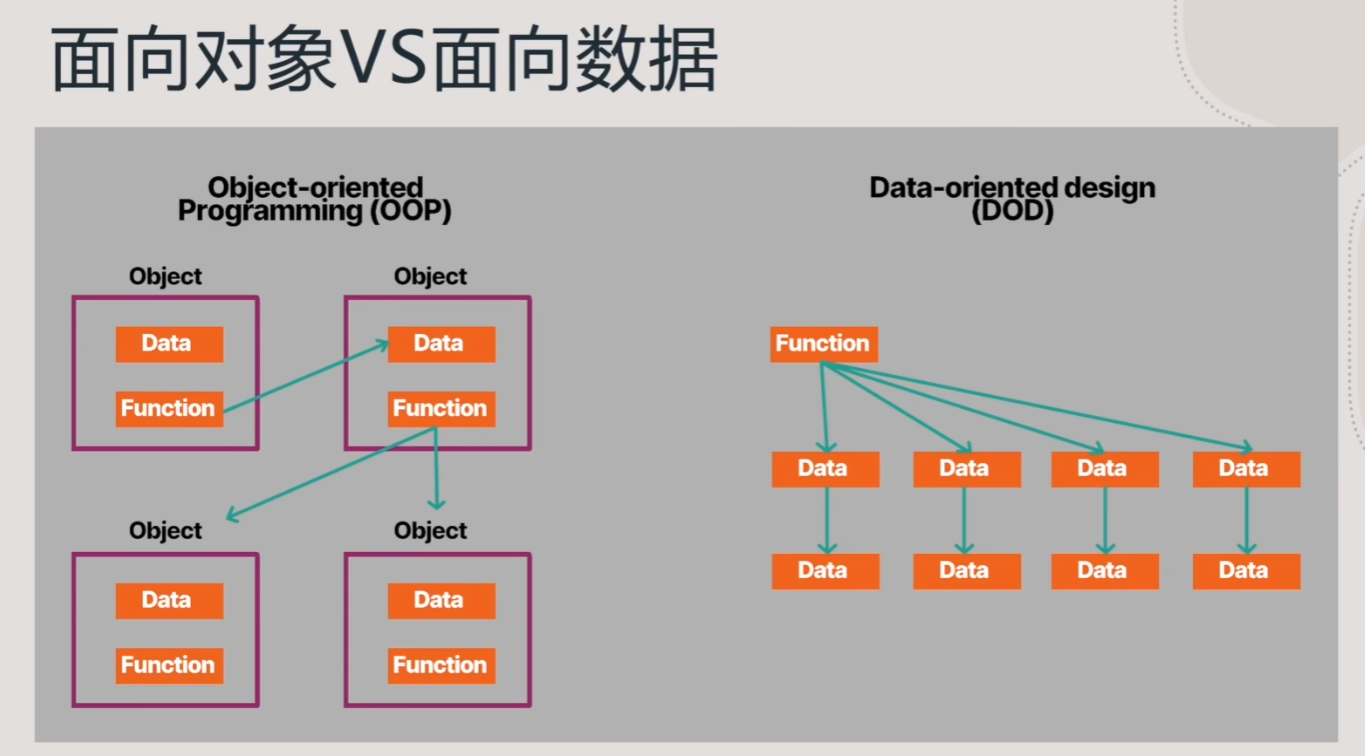
- DOD面向数据设计的本质,可以理解为是面向内存或缓存友好的设计
- 这要从CPU架构与缓存层级结构说起
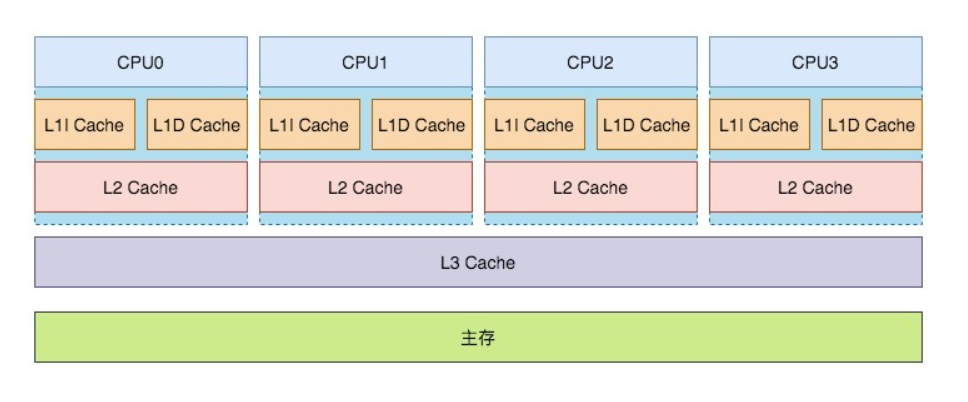
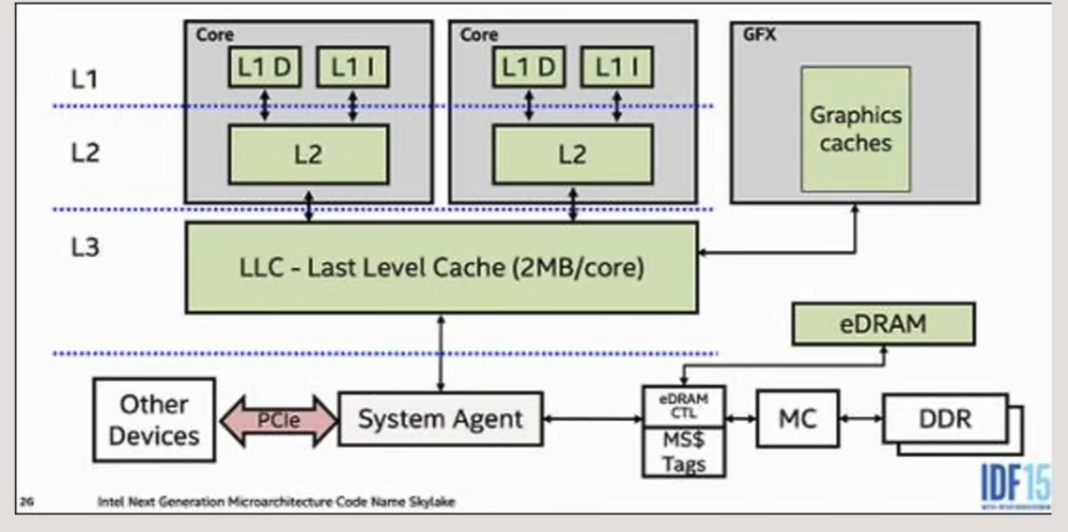
- CPU中会设置L1、L2、L3,3级缓存
- 其中一级缓存为每个指令处理单元独享,又可分为缓存数据的L1 D数据缓存与缓存指令用的L1 I指令缓存
- L2级缓存则为CPU核内多个指令处理单元共享
- L3级缓存则为CPU多个核共享,同时它还负责与内存以及显卡中的显存交换数据
- CPU在执行程序指令时,会通过prefetching来获取指令与数据,每次访问的单位会根据系统与架构的不同而有所差异,一般是32或64个字节,把这个基础大小单位称为catch line缓存行。即使你请求一个字节大小,实际上你会得到一个catch line大小的缓存行数据
- 而在catch缓存内,可以将n个缓存行大小的缓存通过direct map直接映射到同一逻辑缓存行,而逻辑缓存行可以对应n个物理行,来帮助最小化缓存行的抖动。这里的抖动可以理解为 : 扭动指针到每个物理缓存行头
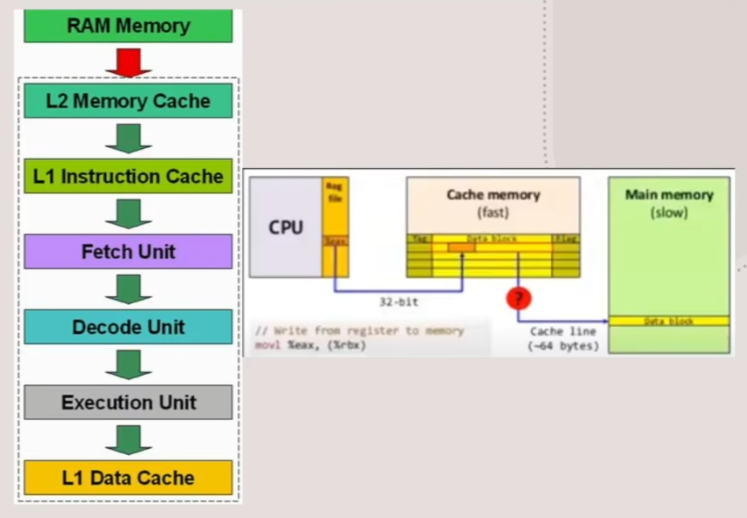
- CPU逻辑处理单元,通过Fetch获得L1 I指令缓存中的指令,再通过Decode解码Execution执行,以及在指令完成后将数据回写到L1 D中,来完成一条程序指令
- 我们可以把Fetch、Decode、Execution这样一个循环时间定义为一个CPU指令的Cycle
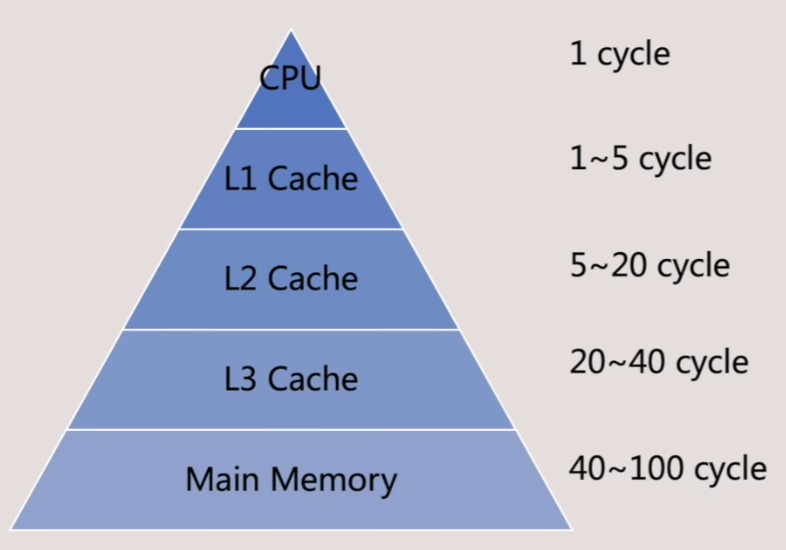
- CPU处理指令时,从不同的缓存Catch中获取数据的时间开销也是不同的,这会导致我们获取的数据在某一级缓存没有命中时,向下一级缓存获取时花费的时间开销可能是数倍时间,甚至是数量级差异的时间开销,因此我们在编写程序时,如何做好面向数据设计,以达到缓存访问友好,对程序性能开销至关重要
Cache的3C与3R
3C即缓存未命中的三种情况
Compulsory misses : 首次读取数据时,不可避免的Miss
Capacity misses : 缓存空间不足时,连续使用期间访问数据过多的话,无法保存所有活动的数据
Conflict misses : 发生访问冲突时,由于数据映射到相同的缓存行,导致缓存的抖动
3C伪代码 :
1
2
3
4
5
6int* data = pointerToSomeData;
unsigned int sum = 0;
for (unsigned int i = 0; i < 1000000; ++i, ++data /*data+=16*/)
{
sum += *data;
}- 当变量i = 0时,第一次进入循环,此时要访问data中的第一个int数据,这时catch中没有数据,会发生第一种情况下的Miss catch,这时需要进行profetching来加载一个catch line数据
- 接下来的第二遍循环会从catch line中加载数据,指令cycle数比第一次要少
- 当data数据足够大、循环次数足够多时(pointerToSomeData、1000000),超过catch大小时会发生第二种情况,缓存不足导致的Miss catch
- 这里只是举例,真实情况不一定发生,而且现在GPU缓存很大,简单的代码触发缓存不足导致的Miss catch情况非常少
- 将 ++data 替换成 data+=16 时,这时会触发第三种缓存抖动带来的Miss
catch,也就是实际数据访问不连续,一次catch line获取的数据并没有你需要的,这种情况发生比较多,尤其是我们使用数组结构体AoS的数据Layout时
3R即3种优化访问catch命中的方法
Rearrange 重新排列(代码、数据) : 更改布局以增加数据空间的局部性
Reduce 减少(大小、缓存行读取) : 更小更智能的格式、压缩,如修改数据类型或使用位计算
Reuse 重用(Cache lines) : 增加数据的时间(和空间)的局部性,主要是对齐、连续访问,减少发生缓存抖动的几率
面向数据设计需要思考的问题

总之,面向数据设计需要我们更了解内存/缓存的特性,需要更了解系统和硬件,需要更了解芯片指令与数据结构设计,与面向对象设计相比,数据比代码更重要
DOTS面向数据设计原则
- 先设计,后编码
- 为高效使用内存与缓存而设计
- 为Blittable Data设计
- 为普通情况设计
- 拥抱迭代