Shader数据类型精度
- Float(32bit):位置与纹理坐标信息
- Half(16bit):纹理坐标与颜色信息
- Fixed(11bit):颜色信息。只针对一些老旧的CPU设计所保留,只在BuildIn管线下适用,SRP下已不支持
尽量使用内置函数
- pow
- normalize
- dot
- inversesqrt
- …
超越函数
一些变量之间关系不能用有限次加、减、乘、除、乘方、开方运算表示的函数,在数学上称为超越函数。这些函数在芯片指令上实现都属于资源密集型函数,在一些低端设备上要慎用、少用,带来的指令开销会比较高
exp
log
sin、cos、tan…
asin、acos、atan、atan2…
sincos
…
指令周期与阶段
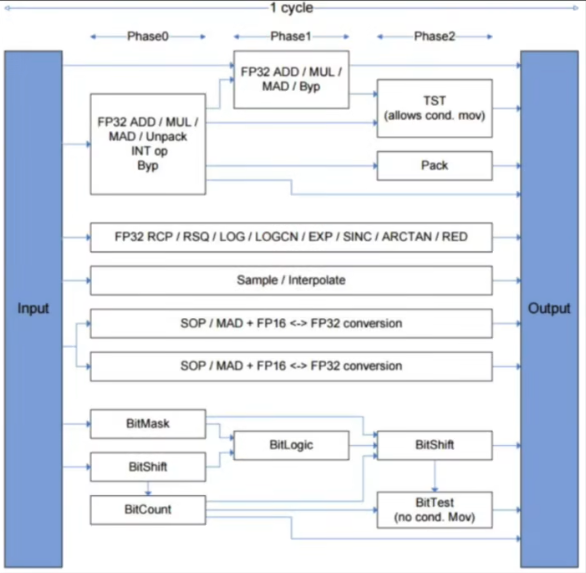
- 一条指令从取指、译码、执行、存储等一系列过程称为一个指令周期,可以理解为图中的cycle
- 但某些简单指令与复杂指令的cycle周期并不一定一样长
- 由于现代GPU Core内核是SIMP为架构的,长度一致的指令cycle更有利于单指令多线程的并行计算
- 因此,为了避免浪费,GPU设计时又将cycle中设计成了多个阶段,也就是多个Phase
- 如果一条简单指令在一个Phase内可以完成,那么在一个cycle内可以合并多条简单指令成一个稍微复杂的指令,如MAD指令以及现在常在XCode中抓取看到的,具有更高精度的FMA指令
指令优化
- mul + add => mad:mad指令就是一个乘法指令加上一个加法指令
- (x - 0.5) * 1.5 ——> x * 1.5 + (-0.75)
- 这样之前的一个减法指令和一个乘法指令会被优化成一个mad指令,指令周期也从两个cycle优化成一个cycle
- 除法 => 乘以倒数(rcp)
- (t.x * t.y + t.z) / t.x ——> t.y + t.z * (1.0 / t.x)
- 对齐
- float3 * float * float * float3 ——> (float * float) * (float3 * float3)
- abs或neg指令输出 => 输入
- abs(a.x * a.y) ——> abs(a.x) * abs(a.y)
- -(a.x * a.y) ——> -a.x * a.y
- saturate指令输入 => 输出
- 1.0 - saturate(a) ——> saturate(1.0 - a)
- min或max => saturate(某些平台)
- max(x,0.0) = min(x,1.0) ——> saturate(x)
- sqrt(x) => rcp(rsqrt(x)) :sqrt改成rsqrt的倒数
- if0 => sign(x):用sign指令代替含零的判断分支语句
- if/else => step(x) lerp(a,b,step(cx,cy)):用step + lerp代替非零的判断分支语句
- sin/cos/sincos << asin/acos/atan/atan2/degrees/radians
- MUL => MAD-MAD-MAD向量乘法指令优化成多个mad指令
- mul(v,m) => v.x * m[0] + v.y * m[1] + v.z * m[2] + v.w * m[3]
- mul(float4(v.xyz,1)) ——> v.x * m[0] + v.y * m[1] + v.z * m[2] + m[3]
- v.x * m[0] + (v.y * m[1] + (v.z * m[2] + m[3]))
- normalize/length/distance都包含一个dot,可以共享
- length(a - b)与distance(a,b)可共享,但与distance(b,a)不共享
- normalize(vec) => vec * rsqrt(dot(vec,vec))
- 50 * normalize(vec) ——> vec(50 * rsqrt(vec,vec))
- 自表达式不共享指令
- v = normalize(v) return v
- mul => mul24:在高版本的shader mode下,乘法指令也有专门用于向量前三个元素相乘的mul24指令进行优化
- fma注重精度的mad
- texture.Load VS texure.Sample:texture.Load在(0,1)的寻址区间会比texure.Sample采样更高效。但Load(tc,offset)>Sample(tc,offset)
其他
- FS => VS
- 避免隐式类型转换,如vector4隐式转成vector3
- Varying数据尽可能组织成向量形式而非标量形式,这样可能会减少一些寄存器的miss catch,而将像素阶段的shader中的逻辑尽可能转到顶点阶段处理,也是均衡vs与ps阶段的gpu负载的一个好手段
- 以上shader指令的优化有个印象就好,不同平台或shader mode的版本差异,可能编译以后的汇编指令条数也有所不同,要看实际汇编条数是否真的减少了,才能确定我们的写法是否能达到优化的效果,这需要在特定的平台上经过长时间的经验积累才能做到如此指令级的优化
其他指令优化
- 针对于分支或循环语句优化的命令

- 如果分支判断的两个分支语句足够简单,我们可以将分支语句展开两个分支同时处理,并选择一个正确结果,我们可以用UNITY_FLATTEN标记分支语句是否展开,用UNITY_BRANCH标记是否真分支需要动态判断
- 一般来说我们可以按照分支语句是否超过六个指令来判断是否展开,如果两个分支语句中指令都小于六个,可以进行展开;如果分支语句大于六个,并且判断结果大多数都走一个分支,那我们可以用UNITY_BRANCH进行标记;如果两个分支走得比较平均,并且两个分支复杂度相同的情况下,在Unity2022下,我们可以充分利用dynamic branch声明shader关键字做运行时动态分支处理
- 循环语句不展开,可以用UNITY_LOOP标记为真循环,如果需要展开,可以用UNITY_UNROLL标记
- 明确需要展开到第几层时,可以用UNITY_UNROLL(_x)带层数参数来标记
Unity Shader中可能导致Early-z失效的操作
- Shader中开启了Alpha Test
- 像素着色时调用了Clip()或Discard指令
- Shader中开启了Alpha Coverage功能
- 在光栅化后修改了像素深度
- 手动关闭了Shader中的Depth Test标记
- Early-z失效的像素过多,带来的后果就是处理像素过多,导致渲染性能下降,因此做一些功能取舍的时候,这个指标是一个关键的参考点
某些平台慎用或推荐用某些内置功能
Alpha Test
Color Mask
sRGB硬件解压
是否使用Alpha Blend代替Alpha Test,或关闭Color Mask功能,都需要在真机上测试才知道,因此移动平台上优化的最大工作量是要考虑多平台、多硬件、多API的兼容,而且是优化手段的兼容
大多数平台目前都支持sRGB格式的硬件解码,所以建议纹理资源导入设置时,勾选使用sRGB格式