Unity中的合批
- 类比将桃子装卸发货的过程。其本质就是按需求组织数据从CPU发给GPU的过程,这些数据包括网格、纹理、Shader变量、材质属性等等。那么这些数据怎么组织、以什么结构组织、以什么频率发送、每次发送多少就是我们Batching要研究的问题了
哪些内容需要Batchaing
- 广义上讲:
- 资源Batching(Mesh、Texture、Shader参数、材质属性):这些资源的合批是做后续某些Batching优化的前提
- Draw call Batching(Static Batching、Dynamic Batching):主要是为了降低GPU的DP操作,能更少地调用绘制命令接口,Unity在这里为我们提供了Static Batching与Dynamic Batching功能
- GPU Instancing(直接渲染、间接渲染、程序化间接渲染):这也是一种绘制优化的手段,用于绘制多个副本网格对象。Unity提供了直接渲染、间接渲染、程序化间接渲染的三种方法接口
- Set Pass call Batching(SRP Batching):之前Draw call Batching是为了减少渲染操作调用次数,而Set Pass call Batching是为了减少渲染状态切换的次数。Unity下为我们提供了减少Set Pass call次数的SRP Batching的功能
资源的Batching
- Mesh:
- 我们可以将临近且不移动的网格对象通过Mesh.CombineMesh合并到一起,合并后用一次网格的渲染调用代替每个网格的渲染调用。但这种方案也有一定的弊端,一旦合并的网格对象较大时,可能造成摄像机剔除不掉的问题以及OverDraw的问题,另外在内存上也会增加一定的开销。CombineMesh主要是针对于静态网格对象
- 如果是动态SkinMesh对象,往往由于美术为了材质表现效果,会通过Material id标记多维子材质,这样导入后会形成多个Submesh,每个不同材质的Submesh会增加一次DrawCall,我们在做平台移植或低端设备兼容时,可以合并多个材质与贴图,并通过通道图方式标记模型不同部位的材质变化
- Texture:
- Unity默认提供了Sprite Atlas贴图,开发者也可以自己通过dcc合并同一模型上多张贴图到一张贴图上以达到纹理合并的方式
- 另外还可以通过TextureArray纹理数组方式向GPU同时传递多张设置相同的贴图资源
- 关于模型、贴图、材质这些资源的Batching,除了Unity官方提供的接口外,资源商店中也有很多资源可以使用
- Shader变量与材质属性
- 在Build In管线下,Unity是通过Material Property Block完成合批的
- 而在SRP管线下则是通过Const buffer来实现的,并且通过定义不同的Const buffer,来控制提交到GPU上的频率,比如PerFrame、PerDraw、PerMaterial等Const buffer标签
Draw Call Batching
- 主要讲Static Batching与Dynamic Batching
- 与手动CombineMesh合并静态网格不同,Static Batching是引擎在构建时,自动将临近可合并的静态网格对象合并到一起,并将合并后的网格转换到世界空间下,并用它们的顶点信息构建一个共享的顶点缓冲与索引缓冲区,然后对可见网格进行简单的绘制调用。
- 值得注意的是:无论是CombineMesh还是Static Batching都不是在运行时合批的,如果你需要在运行时合批,可以通过Unity提供的StaticBatchingUtility.Combine的方法进行运行时合批,这对于一些运行时动态生成网格的对象特别有效,如需要动态关卡生成的Roguelike游戏。运行时合批时,你就不需要勾选BuildSetting中的Static Batching了
- 此外Static Batching功能依旧会有额外的内存开销,所有合批的网格对象都会在内存中保留一份额外的拷贝,是一个典型的空间换时间的优化方案
- Dynamic Batching是对移动的游戏对象进行绘制批处理的手段,以减少绘制调用。Unity在运行时动态网格与动态生成几何体上的动态合批处理方式不同,Unity会将可动态合批的对象构建到一块大的顶点缓冲区中,并根据合批后的数据设置渲染器材质状态,然后将缓冲区绑定到GPU上,对于每个MeshRender是通过缓冲区偏移量来更新提交绘制内容的。做个类比,可以把静态网格对象理解成硬桃子,动态网格对象或动态生成几何体理解成软桃子,硬桃子量大、储存期长,你可以用火车起运,运输目的地可以较远,用途也更广一些;而软桃子为了避免腐烂,只可以做短距离小范围运输,甚至要就地加工,用途上会有更多限制。Dynamic Batching主要是为了一些低端、旧设备性能优化考虑的,在现代消费级硬件上,Dynamic Batching在CPU上的调用开销可能会更大,因此是否开启动态合批选项还需要在目标设备上测试使用,并不是无脑开启的
- 总之,无论是Static Batching还是Dynamic Batching,在使用上都有一些使用限制,稍不注意就会造成无法合批的现象
GPU Instancing
- GPU实例化也是一种Batching,用于渲染网格的多个副本。它是将基础网格对象传递给GPU后充分利用Instancing Buffer的方法,传递多个网格实例位置、朝向、颜色等其他属性构成的Instancing Buffer到GPU,避免了反复传递多个基础网格对象在世界空间下变换后的各种顶点数据和其他额外数据,所有的实例都会引用同一个基础网格对象,非常适合创建植被、石头等场景中大量重复的网格对象
- GPU Instancing在Unity Build In管线与SRP管线下都支持,只不过在SRP管线中无法与SRP Batcher兼容,二者只能选择一个开启
- 需要开启GPU Instancing时,我们需要保障对应网格对象的材质中Enable GPU Instancing选项的开启

- 如果是自定义Shader,我们还需要定义Instancing Buffer的结构
- 值得注意的是,如果基础网格对象顶点数较少时,由于无法充分利用GPU资源,可能会导致性能不够理想,因此,对于顶点数较少的网格,我们需要反复测试,一般情况下不建议使用GPU Instancing
- Unity可以在脚本中通过直接(DrawMeshInstanced)、间接(DrawMeshInstancedIndirect)、间接程序化(DrawMeshInstancedProcedural)三个接口自定义绘制Instancing
- 其中第一个接口DrawMeshInstanced使用简单,但有实例化数量的限制;第二、三个更灵活一些,但实现相对复杂,可以在Unity文档中学习使用
Set Pass Call Batching
- 只有一类:SRP Batcher。顾名思义其仅能在SRP管线下开启
- 它可以显著减少Unity为使用相同着色器材质,准备和调度绘制的CPU时间开销
- 类比桃子运输装卸场景就是,使用什么交通工具、多少频率发一次货性价比最高
- 其核心是需要图形API支持的Const Buffer。这个Const Buffer中放什么、每个元素大小、Const Buffer总体大小以及什么时机以什么频率将Const Buffer中的内容提交给GPU,都是会影响最终性能的
- 好在Unity已经为我们定义好了一些Const Buffer类型,如
- UnityPerCamera
- UnityPerFrame
- UnityPerPass
- UnityPerDraw
- UnityPerDrawRare
- UnityPerMaterial
- 上面几类SRP已经定义好的Const Buffer包含了引擎内置的一些Shader变量与属性,同时也指定了提交到GPU上的频率
- 而需要开发者定义的只有UnityPerMaterial这类的Const Buffer,这类Const Buffer只有在其定义属性发生变化时才会被提交到GPU上
- 我们需要将自定义的着色器变量与材质属性添加到这类的Const Buffer中,不能有在Const Buffer之外定义的其他属性或Uniform变量,确保SRP Batcher字段是compatible的,这一点非常重要
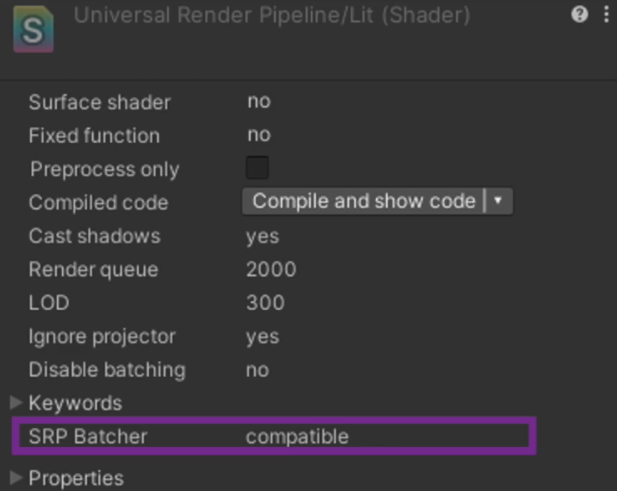
- 在SRP管线下强烈建议开启SRP Batcher功能,如果不使用此功能,个人觉得完全没必要升级到URP或HDRP管线
- 在URP管线中,自带的某些Const Buffer在定义上可以做一些精度上的优化,以提高Shader的指令效率
Batching优化顺序及优先级
- 资源Batching > SRP Batching = Static Batching > GPU Instancing > Dynamic Batching